


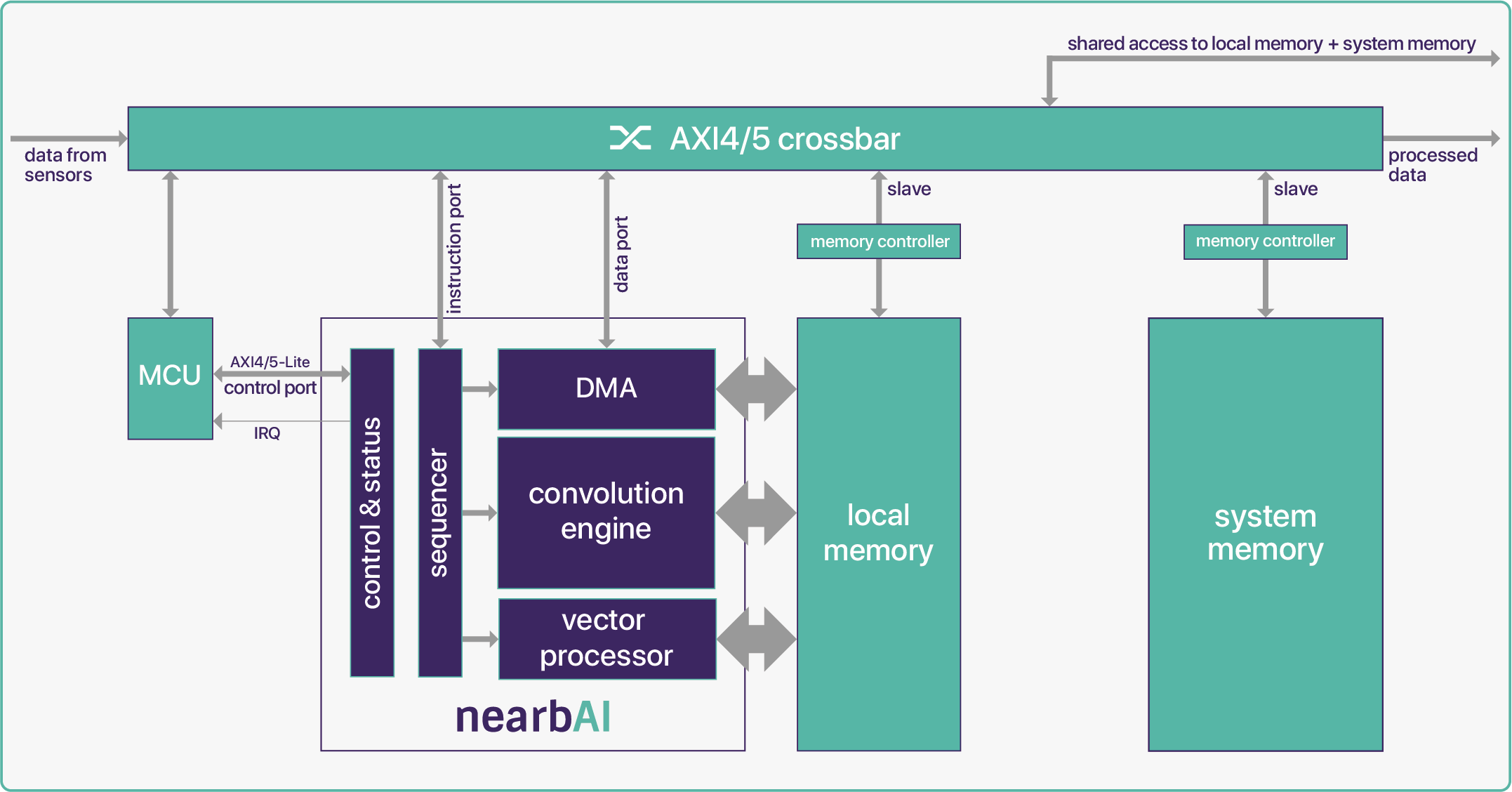

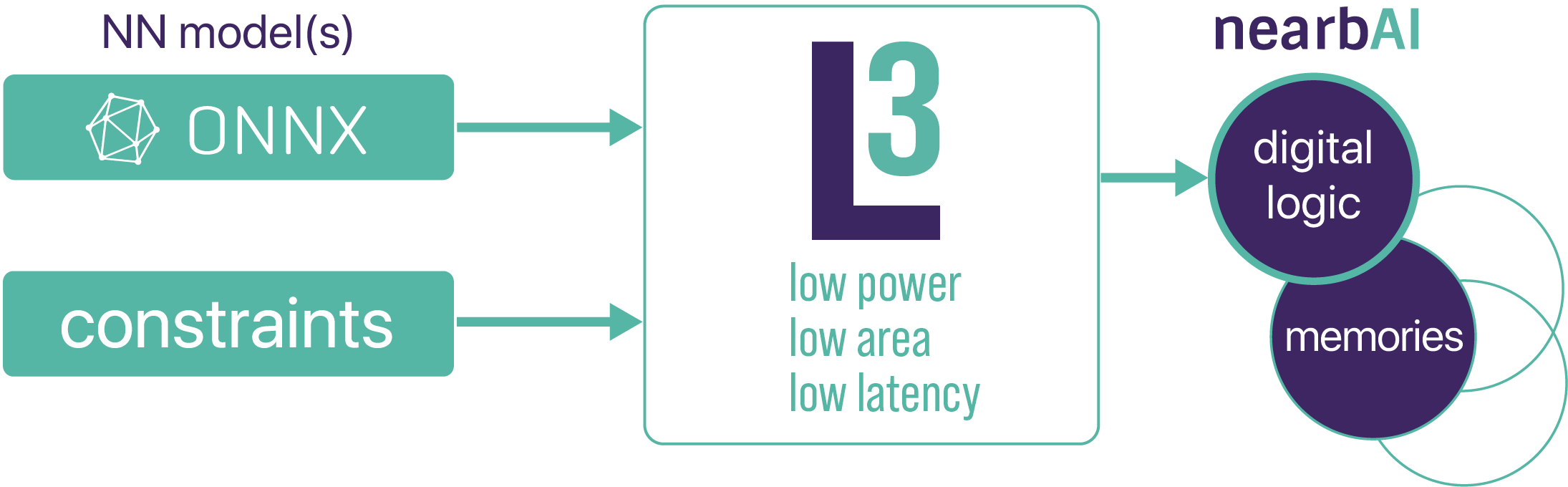
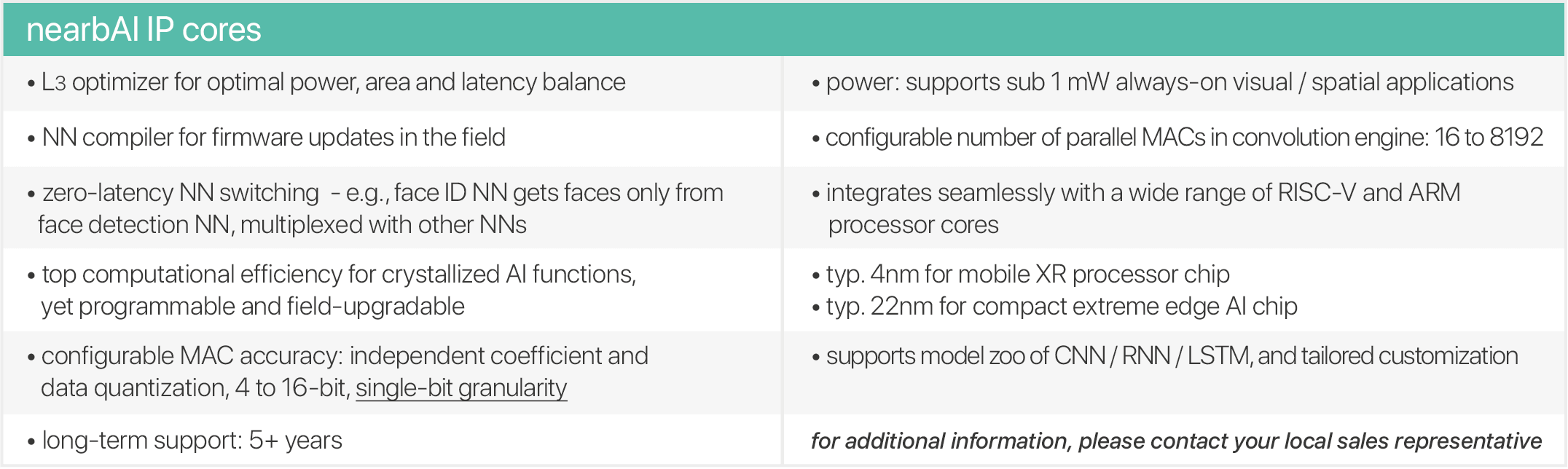
nearbAI is unique, delivering best-in-class solutions for battery-powered mobile, XR and IoT devices. It builds on more than three decades of DSP and image sensor chip design. Our mission is to provide customers with IPs that perfectly fit their specifications, offer outstanding performance, and are seamless to integrate right through to tape-out.
easics is committed to bringing the most advanced technology and solutions to market. With nearbAI, along with our partners and customers, we are pushing the latest AI innovation to the extreme edge
easics is committed to bringing the most advanced technology and solutions to market. With nearbAI, along with our partners and customers, we are pushing the latest AI innovation to the extreme edge

ramses valvekens
CSO & managing director
easics
easics





feel free to get in touch with us
complete the form below and we will contact you within 48h
start the collaboration with us
and we will deliver the best solution
based on your needs
and we will deliver the best solution
based on your needs
easics nv
diestsevest 32 box 2b
3000 leuven, belgium
diestsevest 32 box 2b
3000 leuven, belgium
vat: BE 0444.501.015